服務器連夜恢復數據:原因、策略、流程、團隊與效果評估
瀏覽量: 次 發布日期:2023-11-06 03:19:30
服務器連夜恢復數據:原因、策略、流程、團隊與效果評估

==================================
一、事故發生原因
-------
在這次的事件中,我們的服務器在凌晨時分出現了嚴重的故障,導致數據無法正常讀取和寫入。經過仔細的分析和排查,我們發現事故的主要原因是:
1. 硬件故障:服務器的硬盤出現故障,導致數據存儲的完整性受到影響。
2. 軟件故障:服務器的操作系統和數據庫軟件出現未知錯誤,影響了數據的正常操作。
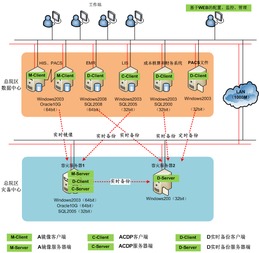
二、數據備份策略
--------
在這次的數據恢復過程中,我們得益于之前制定的完善的數據備份策略。我們的備份策略主要包含:
1. 每日備份:我們每天都會對重要數據執行備份操作,確保數據的實時更新。
2. 周備份:每周我們會進行一次全面的數據備份,以防止日常備份出現遺漏。
3. 月備份:每月底,我們會進行一次全面的數據檢查和備份,確保數據的完整性和可恢復性。
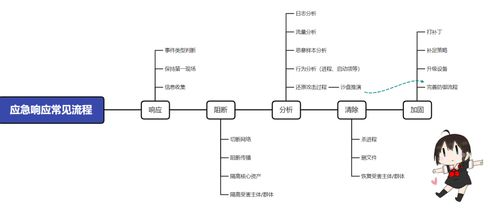
三、緊急響應流程
--------
在服務器故障發生后,我們的緊急響應流程如下:
1. 故障報告:我們的運維團隊會在第一時間收到服務器故障的報告,并立即啟動緊急響應流程。

2. 備份恢復:使用最新的備份數據恢復服務器,確保數據的完整性和準確性。
5. 再次備份:修復完成后,再次進行數據備份,確保數據的完整性。
四、技術人員團隊

--------
五、恢復效果評估

--------
經過技術團隊的不懈努力,服務器在事故發生后的24小時內成功恢復正常運行。我們對恢復的數據進行了詳細的檢查和對比,確認所有重要的數據都已成功恢復,且與事故發生前的數據狀態一致。在此基礎上,我們進一步進行了系統性能的測試和評估,確保服務器的性能恢復到最佳狀態。
六、總結與反思
--------
這次的數據恢復事件雖然已經過去,但我們對這次事件的總結和反思不能停止。我們要對現有的備份策略進行再次審視和優化,尤其是在硬件和軟件故障的預防方面。我們要對現有的緊急響應流程進行細化和完善,以便在未來的類似事件中能夠更加高效地進行響應和處理。我們要對技術團隊的應急處理能力進行進一步的提升和培訓,使他們能夠在未來的工作中更好地發揮作用。
通過這次事件,我們深刻認識到數據備份和服務器維護的重要性。對于任何一家企業來說,數據的丟失無疑是一場災難。因此,我們將把這次的經驗教訓轉化為實際行動,進一步提升我們的數據安全保障能力。同時,我們也要感謝那些在這次事件中付出辛勤努力的技術人員們,他們的專業精神和執著是我們度過這次難關的重要保障。





 QQ客服
QQ客服